「digzyme Custom Enzyme Lab」で期待される実用化例:糖鎖構造構築および難分解性物質へのアプローチ
はじめに
2025年5⽉21⽇(水)、22(木)、23 ⽇(金)
と3日間に渡り開催されたifia JAPAN 2025。
昨年と同様、弊社の代表取締役、渡来が出展者プレゼンテーションを行いました。
その様子をYOUTUBEで公開いたしましたので、ぜひご覧ください。
今回の出展者プレゼンテーションでは、2025年5月21日にローンチされた「digzyme Custom Enzyme Lab」についてご紹介しました。当日は、DRY技術(バイオインフォマティクス解析)とWET技術(実験検証)という二つの技術的アプローチに触れつつ、プラットフォーム全体の概要をお伝えしました。
本記事では、その中で取り上げた『「digzyme Custom Enzyme Lab」で期待される実用化例』2件について、渡来の視点を通じて、各事例における技術的ブレイクスルーやin silico設計の裏側をQ&A方式で詳しくご紹介します。
当日のプレゼンテーションでは全体像のご紹介にとどまりましたが、本記事を通じて、「digzyme Custom Enzyme Lab」の実力と可能性をより具体的にご理解いただける内容となっております。ぜひ最後までご覧ください。
まずは一つ目の事例についてです。

「digzyme Custom Enzyme Lab」で期待される実用化例1
Q.この成果の最も大きな意義は何だと考えていますか?
A.糖質は、構成する糖の結合様式の違いによって物性の差が生まれます。in silico技術で、目的の糖鎖構造を作る酵素を狙って探索ができた例は学術的にも稀で、かつ10個という少数の実験で発見できたことは非常に価値が高いと考えています。
Q.これまでのアプローチと比べて、今回のアプローチは何が革新的だったのでしょうか?
A.本件は、結果的には、当時のAlphaFold2に代表される深層学習(DL)ベースの構造予測技術に対して、弊社独自の詳細な分析技術を適用した点が役に立ちました。これまでのhomologyベースのモデルでは、糖鎖構造を作り分ける微妙なタンパク質構造の違いまでは予測することが困難でしたが、当時のAI技術によりそれらの特徴を一定程度捉えられたと考えています。
(なお、現在の生成モデルを用いた最新のAI技術とはギャップがあるため、本稿では便宜的に「AI」とまとめて表現しております。)
Q.チームや関係者のどのような努力がこの成果につながったと思いますか?
A.担当の研究員が、顧客ニーズを詳しく深堀りして当該酵素のスクリーニング基準をうまく設定し、基盤開発メンバーと連携することで解析プログラムを個別に作成し、この成果につながりました。当社では、既存プラットフォームだけで達成できない課題に対しても、フレキシブルにツール開発を行える点が強みだと思っています。
次に、三菱ケミカル株式会社と共同で行った、二つ目の事例についてです。
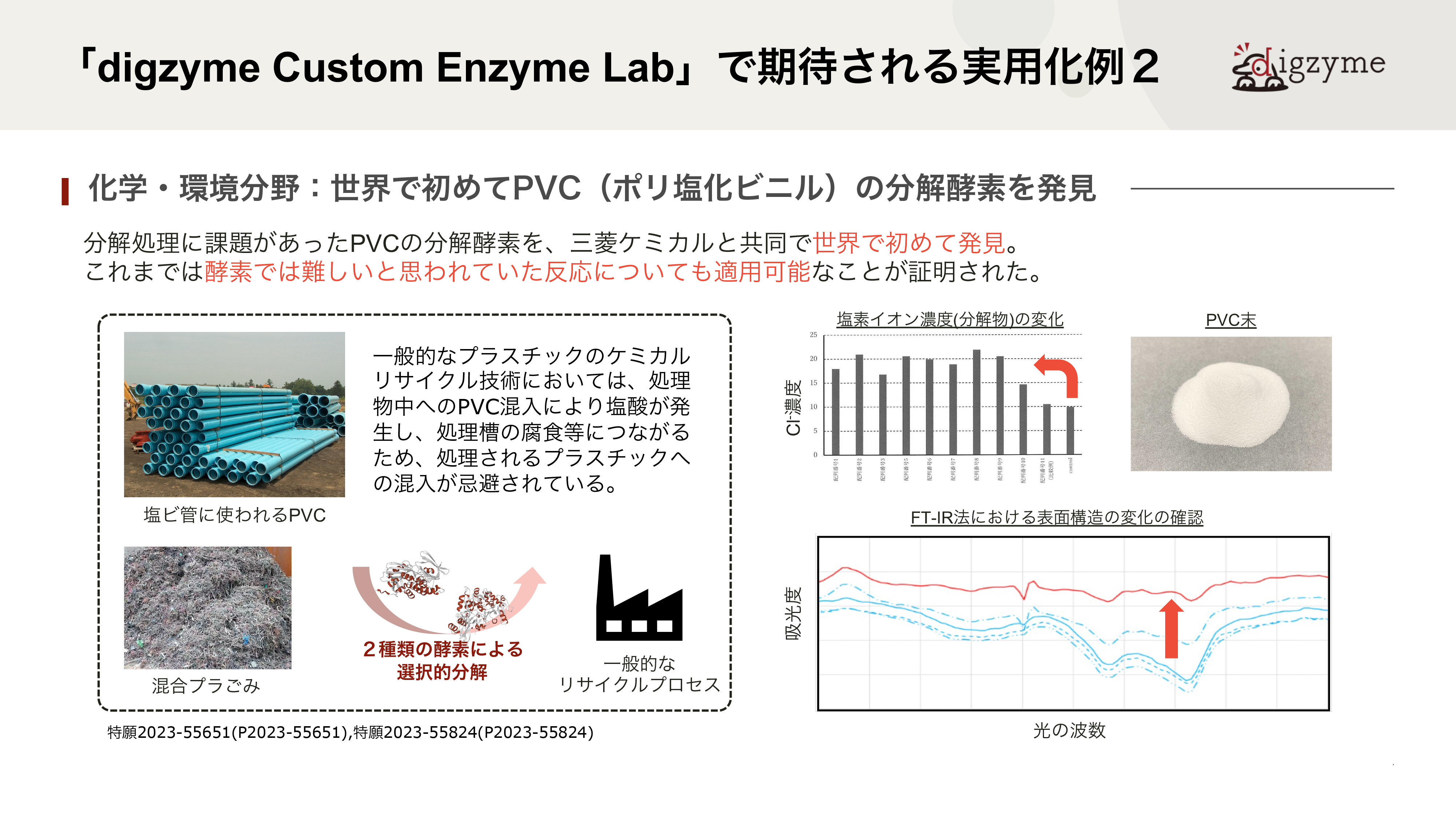
「digzyme Custom Enzyme Lab」で期待される実用化例2
Q.この成果の最も大きな意義は何だと考えていますか?
A.PVCは20世紀から本格的な生産が始まった自然界にない物質で、天然の微生物が進化の過程で分解機構を獲得していないと仮定すると、最適化された酵素は天然からは見つからないはずです。一方で、生物は休眠遺伝子を含めて”最適化されていない”さまざまな遺伝子をゲノムに保有しており、結果として環境変化への適応に活かされるとされています。本件は、その環境適応に寄与しうる酵素をin silicoで人工的に見つける問題とも捉えられるため、難易度が高いテーマでした。
Q.従来、このような酵素を発見するにはどれほどの時間やコストが必要でしたか?
A.近年、人工的なプラスチックの分解酵素を、集積培養に近い形で見出す研究がいくつか見られます。例えば、ある樹脂を海底に一定期間沈めておき、引き上げた後に分解の様子を観察したり、バイオフィルムに含まれる微生物を単離培養したりします。うまくいく場合には、分解酵素を持つ微生物が見つかるので、ゲノム解析やBACライブラリ作成などを通じて分解酵素を同定することが出来ますが、分解が遅いという性質上、どうしても年単位での時間がかかってしまいます。もちろん、分解が観察されず、うまくいかないケースも数多くあると思っています。in silicoでの探索は長くても半年程度で済むため、このような実験時間が長くかかってしまう対象に対してもある程度効果的に用いることが可能です。
終わりに
渡来は、今回の出展者プレゼンテーションを振り返りながら、次のように語っています。
「『digzyme Custom Enzyme Lab』でも、事前の準備期間の中で、これらの共同研究ケースのようなin silicoライブラリを作成して進めていくことができます。高精度のライブラリから精製酵素を試したいお客様におすすめしたいサービスです。」
このコメントが示すように、バイオインフォマティクスを基盤とした酵素設計アプローチは、限られたリソースの中でも実用的な酵素開発を加速しうる可能性を持っています。
今後さらに、酵素の多様な分野への応用が進む中で、「digzyme Custom Enzyme Lab」はその中核を担う技術基盤として重要な役割を果たすと考えられます。
ifia JAPAN 2025会場で頂戴したご質問への回答まとめ
はじめに
食品事業部の村瀬です。
弊社は、2025年5月21日(水)〜23日(金)に東京ビッグサイトで開催された「ifia JAPAN 2025 第30回 国際食品素材/添加物展・会議」(主催:食品化学新聞社)に、昨年に続いて出展いたしました。
会期中は、弊社の技術に高い関心をお持ちの多くの来場者の方々と、直接お話しできる貴重な機会となりました。
出展ブースでは、そうした皆さまに向けて、弊社の最新の取り組みをご紹介していましたが、なかでも大きな目玉となっていたのが、新しいソリューション「digzyme Custom Enzyme Lab」のローンチについてです。(詳しくはプレスリリースをご覧ください:https://prtimes.jp/main/html/rd/p/000000018.000050097.html)


ローンチにあたり、想定を上回る多くのご反響をいただき、出展ブースでは連日、多くの方から具体的なご質問やご相談をいただき、終始活発な対話の場となりました。
そこで今回のテックブログでは、「digzyme Custom Enzyme Lab」のローンチを記念した特別編として、会期中にいただいたご質問の中から、特に多かった内容をピックアップし、回答と合わせてQ&A形式でご紹介します。
本ソリューションにご興味をお持ちの方はもちろん、「酵素を使った開発に関心はあるけれど、何から始めたらよいのかわからない」という方にも、ヒントとなる内容です。ぜひ最後までご覧ください。
Q:「digzyme Custom Enzyme Lab」は、どんな開発テーマに利用できる?
A:「digzyme Custom Enzyme Lab」は、「現行の酵素を用いた製造法の効率向上」のような具体的な開発テーマから、「(酵素を用いた)新規食品素材開発」のような抽象度の高い開発テーマにもご利用いただけるソリューションとなっております。精製酵素サンプル提供とお客様での酵素評価のフィードバックを繰り返し行うことで、随時開発方針の調整が可能です。
Q:提供される精製酵素サンプルについて、どんな情報が提供される?
A:基本的な酵素活性の有無、プロファイル(至適温度、至適pH、熱安定性、pH安定性)の確認を弊社で行い、サンプル提供と併せて提出いたします。実際の評価系での実証実験については、お客様ご自身で確認することができます。
Q:提供される精製酵素のサンプル量はどれくらい?
A:開発テーマごとにもご相談となりますが、典型的には、酵素溶液として~mL、タンパク質として~mg単位でのご提供となります。
Q:初期開発期間はどのように決まる?
A:お客様がご希望するテーマについて、事前に弊社で開発方法の検討・調査を行い、初期開発期間を決定いたします。基本的には、2〜6ヶ月の間で初期開発(in silico酵素デザイン〜初回提供精製酵素サンプル製造)を行います。
Q:遺伝子組み換え技術を利用しない方法での酵素開発も可能?
A:可能です。詳細は、「digzyme Express」のご紹介ページ(https://www.digzyme.com/cms/wp-content/uploads/digzyme_Express_ol.pdf)をご参照ください。
Q:「digzyme Custom Enzyme Lab」は食品産業向けのみのソリューション?
A:「digzyme Custom Enzyme Lab」は、食品産業だけでなく、化学産業など業種を問わずご利用いただけるソリューションです。
Q:提供された精製酵素サンプルの中から、希望に合う酵素が見つかった場合、その後はどうなる?
A:「digzyme Custom Enzyme Lab」で開発された酵素については、シームレスに製造に向けた開発へ進めていくことが可能です。digzymeでは、該当酵素の製造技術開発・各種認可まで、お客様の開発テーマの事業化に最後まで伴走いたします。
Q:開発した酵素ライブラリの知財の扱いはどのようになっている?
A:digzyme Custom Enzyme Labで開発した酵素の中から有望な酵素を見出すことができ、更にそれを利用した事業化をご検討される際には、ご要望に応じて柔軟に対応させていただきます。
以上、「digzyme Custom Enzyme Lab」でご提供致しております内容についてご回答申し上げましたが、実際の開発の際には、お客様のご要望に応じて柔軟に対応させていただきますので、お気軽にご相談ください。
今回のQ&Aは以上となります。
最後までお読みいただき、ありがとうございました。
ご不明な点やご質問がありましたら、ぜひ下記のコンタクトフォームよりお気軽にお問い合わせください。
【▼コンタクトフォーム】
https://www.digzyme.com/contact/
ifia JAPAN 2024会場で頂戴したご質問への回答まとめ
食品事業部の村瀬です。
弊社は、2024.5.22(水)~24(金)、東京ビッグサイトにて開催された
「ifia JAPAN 2024 第29回 国際食品素材/添加物展・会議」
(食品化学新聞社主催)に出展いたしました。
展示ブースにお越しいただいた皆様、誠にありがとうございました。
この記事では、展示期間中、皆様から頂戴したご質問の中から
特に多くいただいた内容をご紹介し、回答いたします。
ぜひ最後までご覧ください。
Q:何ができる会社ですか?
A:お客様のご要望に応じて、新規酵素探索、酵素改変を行います。
従来の手法とは異なる、独自のバイオインフォマティクス技術を用いた
スピーディーな酵素開発によって、酵素メーカー、食品メーカー両者にとっての
イノベーションアクセラレーターになることができると考えています。
Q:具体事例はありますか?
A:ケミカル用途では、ユーザーが必要とする新規酵素の探索や、
酵素の大幅な活性向上に成功した事例がございます。
食品用途では、現在複数のお客様より具体的なテーマをいただき
実際にお取り組みさせていただいている状況です。

Q:digzyme Spotlight(酵素改変型プログラム)では、酵素の何の性質が改変できる?
A:活性向上、耐熱性向上、至適pHの改変などが考えられます。
基質特異性の改変は状況に応じて、digzyme Moonlight(酵素探索型プログラム)を使用します。
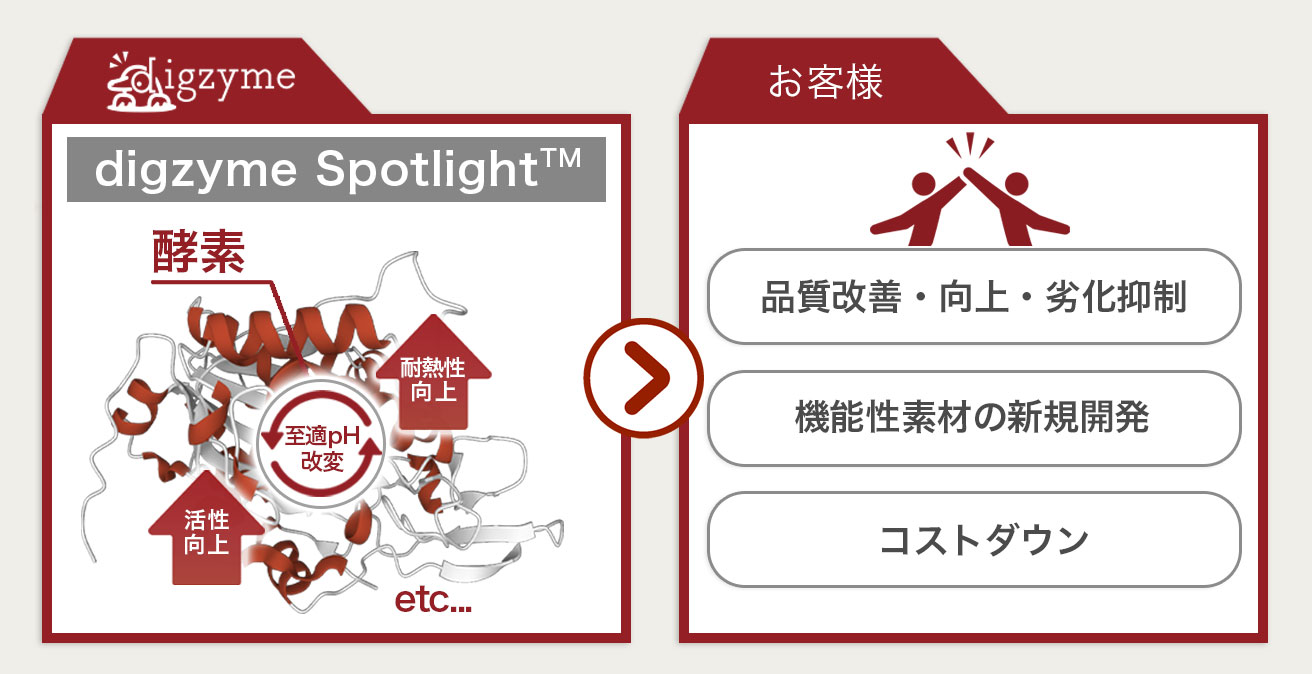
Q:どのような流れで開発を進める?
A:お客様の状況に応じて、スタートとゴールを設定させていただきますが
主な流れは以下となります。
1.開発コンサルティング:お客様の課題をヒアリングし、ターゲットとする酵素を選定します。
2.酵素デザイン:スーパーコンピューターを用いて、ターゲットとなる酵素のデザインをします。
3.酵素ライブラリ提供:コンピューター上でデザインした酵素を
実際に微生物を用いてラボスケールで製造し、目的に沿った酵素かを検証・確認します。
4.酵素の生産提供:製造スケールをラボからプラントへスケールアップし、
製品として酵素を安定供給できる体制を整備します。
当記事でのQ &Aは以上です。
それでは、最後までご覧いただきありがとうございました。
その他のご質問などございましたら、下記のコンタクトフォームよりお問い合わせくださいませ。
【▼コンタクトフォーム】
https://www.digzyme.com/contact/
Spotlightによる酵素変異体の活性予測精度を先行研究と比較
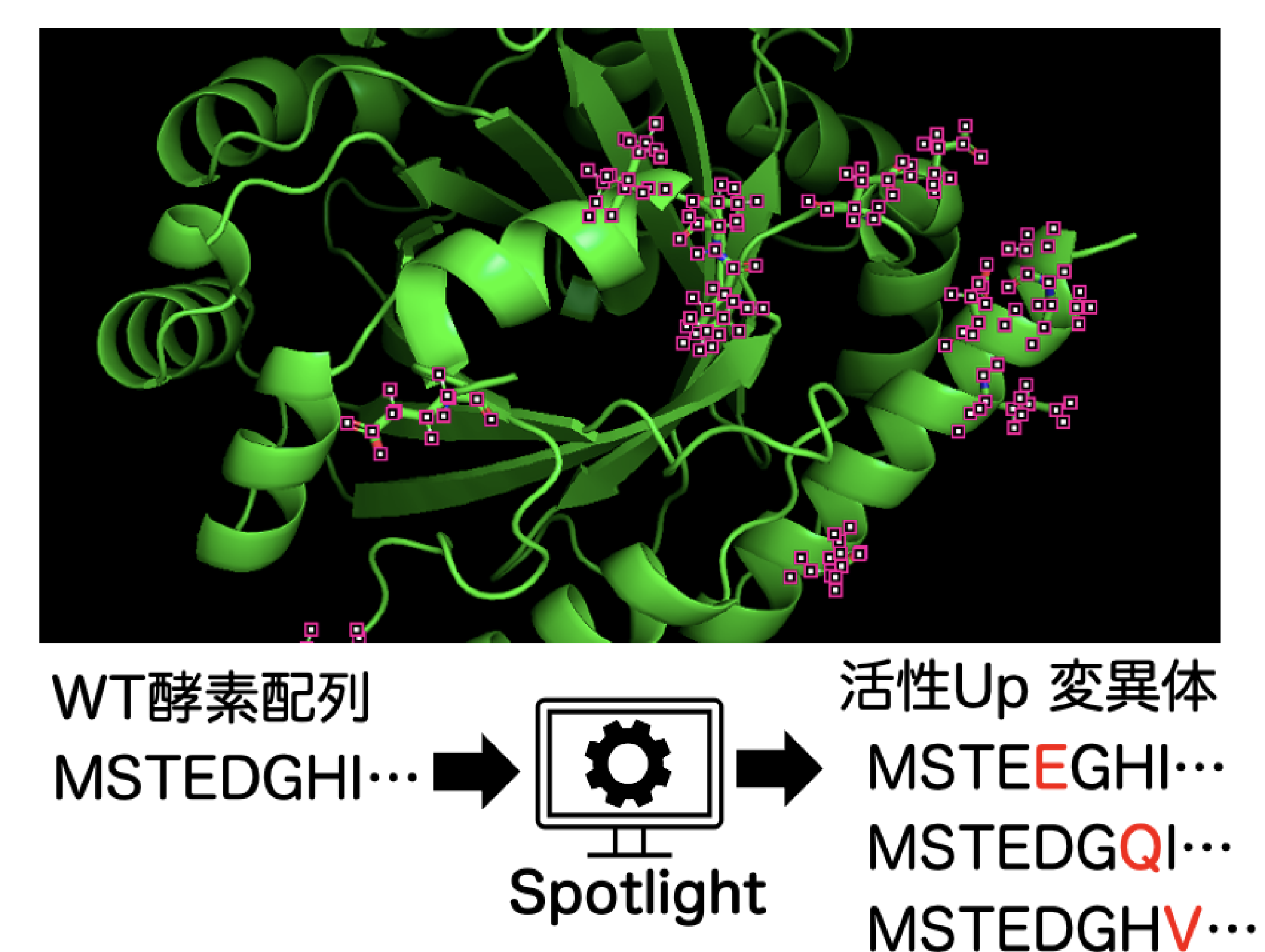
はじめに
事業開発部の礒崎です。弊社では酵素の活性や耐熱性などのプロパティを向上させる変異体を機械学習モデルを用いて提案するSpotlightというサービスを提供しています。様々な酵素を使って学習済みのモデルに、社内または社外から依頼を受けた目的の配列をインプットすることで活性などが向上する変異体を予測します。今回のtechblogではこのSpotlightの変異体の活性予測精度が先行研究と比較してどの程度なのか検証しました。
比較対象に使用した先行研究
Li et al., 2022では、酵素のアミノ酸配列と化合物を入力情報としてkcatを予測する機械学習モデルを構築していました。今回の比較ではこの機械学習モデルアルゴリズム(DLKcat)を用い、かつ、比較を平等にするためにSpotlightと同じ教師データであるBRENDAのkcat エントリーを使ってモデルを再構築しました。この再構築したDLKcatにより予測した変異体のkcatの値とSpotlightで予測したkcatの値のいずれが実測値とより近いか比較しました。今回使用したBRENDAのエントリーにはwild type (WT) と単変異体のみが含まれるように抽出し、変異1つに対する感度が2つのモデルでどれくらい違うかに注目して比較しました。
結果
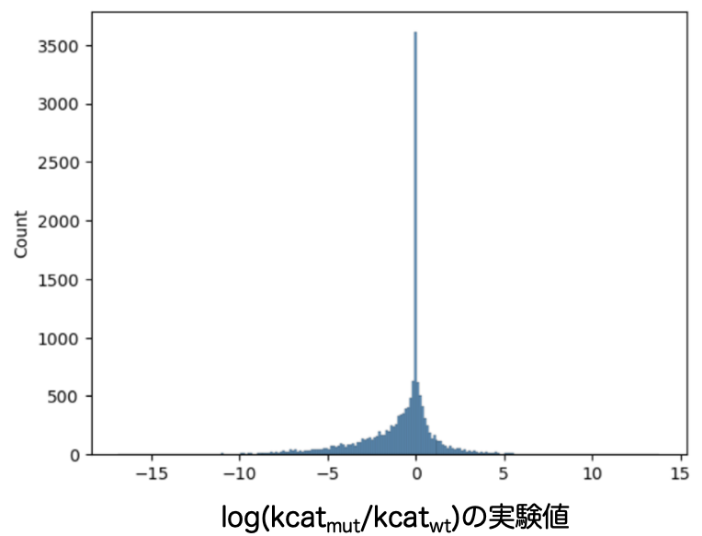
1. BRENDAのkcat (=Turnover Number)のデータを用いた学習モデルの構築
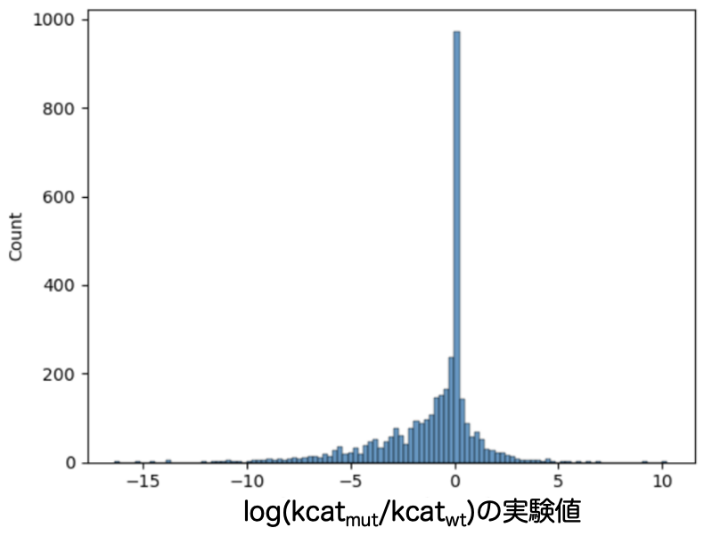
BRENDAのkcatが記載されている変異体、そのWTの配列のエントリーおよびkcatを測定した化合物の情報を抽出し、これらを酵素ファミリーに偏りが生じないように、かつ、およそ教師データ:テストデータ= 3 : 1になるように分割しました。分割後の教師データではkcatが向上しているエントリーが3969、変化しないエントリーが2985、減少しているエントリーが8296でした(図1)。分割後のテストデータではkcatが向上しているエントリーが792、変化しないエントリーが748、減少しているエントリーが1926でした(図2)。
2. DLKcat・Spotlightで予測したkcatの変異体/WT比率の評価
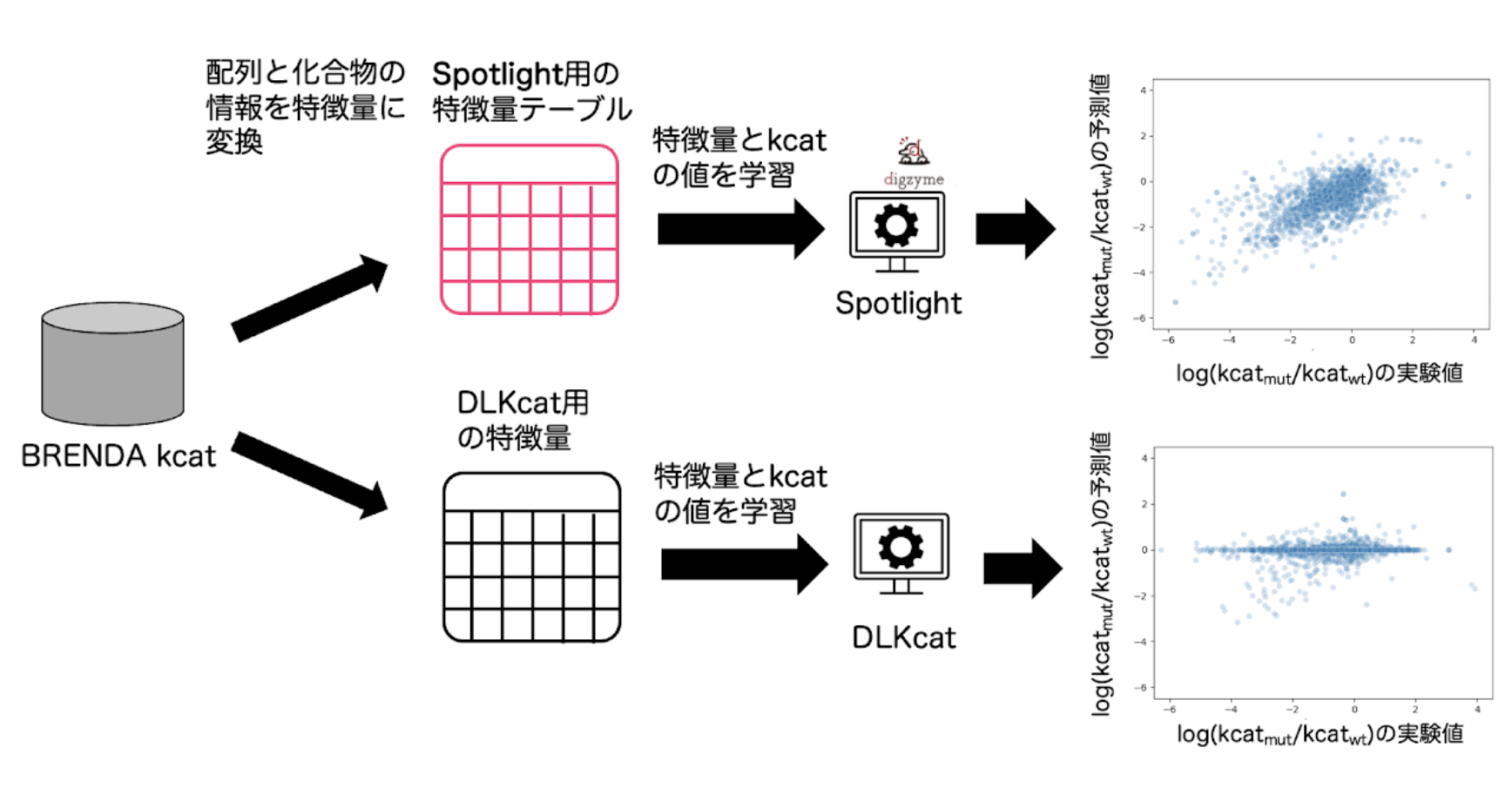
抽出したBRENDAのエントリーの情報をDLKcatが要求する特徴量の形に変換し、教師データの中のkcatの実験値と合わせて学習モデルを構築しました。Spotlightでも同様にこれらのエントリーをSpotlightが要求する特徴量の形に変換して、kcatの実験値と合わせて学習モデルを構築しました(図3)。
DLKcatで予測した変異体のkcatとWTのkcatの比率は実測値と予測値の間でピアソン相関係数が0.18でした(図3)。DLKcatにおいて予測した変異体とWTのkcatの比率が実測値と良く相関しなかった理由は、DLKcatでは特徴量として配列の全長をベクトルに変換しているため1アミノ酸の違いが特徴量に現れづらくなっているからであると考えています。Spotlightで予測した変異体のkcatとWTのkcatの比率は実測値と予測値の間でピアソン相関係数が0.66でした(図3)。弊社のSpotlightでは特徴量に変異体としての性質を大きく反映できる工夫をしてあるため、単変異体のエントリーであってもWTからの1変異による変化を正確に予測することができています。
終わりに
弊社のSpotlight™では先行研究と比べて、単変異体というWTから1アミノ酸しか違わないようなケースでも、その変化を正確に反映してより実験値に近い値を予測可能であるということが明らかになりました。
謝辞
今回の酵素活性予測の精度比較には以下の論文のデータを利用させていただきました。
Li et al., (2022) Deep learning-based kcat prediction enables improved enzyme-constrained model reconstruction. Nature Catalysis.